|
March 26,
2003
The clues for Yamhill
(
by Hans de Vries )
64
bit processing using twin 32 bit cores
Three
clues for Yamhill seem to provide substantial prove.
The
industry has speculated a year now on the existence of 64 bit extensions
to the x86 ISA in Intel's future 90 nm processor codenamed Prescott. We
could show in our March 6 article that Prescott contains two instead of
one 32 bit integer execution cores. The question arises for the purpose
of such a second core? In fact there are many different
possibilities: Use it to run a separate trace to improve hyper threading.
Use it to check the results of the first core (IBM has a processor that
does just this). And of course, Yamhill, is just one of them. searching
for clues we started looking at the highest resolution die-plot of the
Pentium 4 we could find and try if we could make some sense of all these
little artificial colored rectangles and lines. (The photo shows 5
micrometer details) We made progress, studied code optimization manuals
for clues, Went through all the presentations, then looked at Pentium 4
related patents from known P4 architects, made more progress, gained
confidence and started to write an article about the Integer execution
core with the die photo as the visual base. This long article will be
published in the near future. For now we have stumbled on a number of
clues that seem to provide substantial prove for the existence of
Yamhill. If (or when) it will be enabled is a different question. They
might even call it the Pentium 6.... (Tejas = 7, Nehalem = 8)
(
Edit, March 29,2003: The rumors
are that it will be enabled in Potomac.
The
MP version for systems with more than 2
processors in late 2004 )
And
then now the clues, They are handled in more in detail later in the
article.
|
Clue
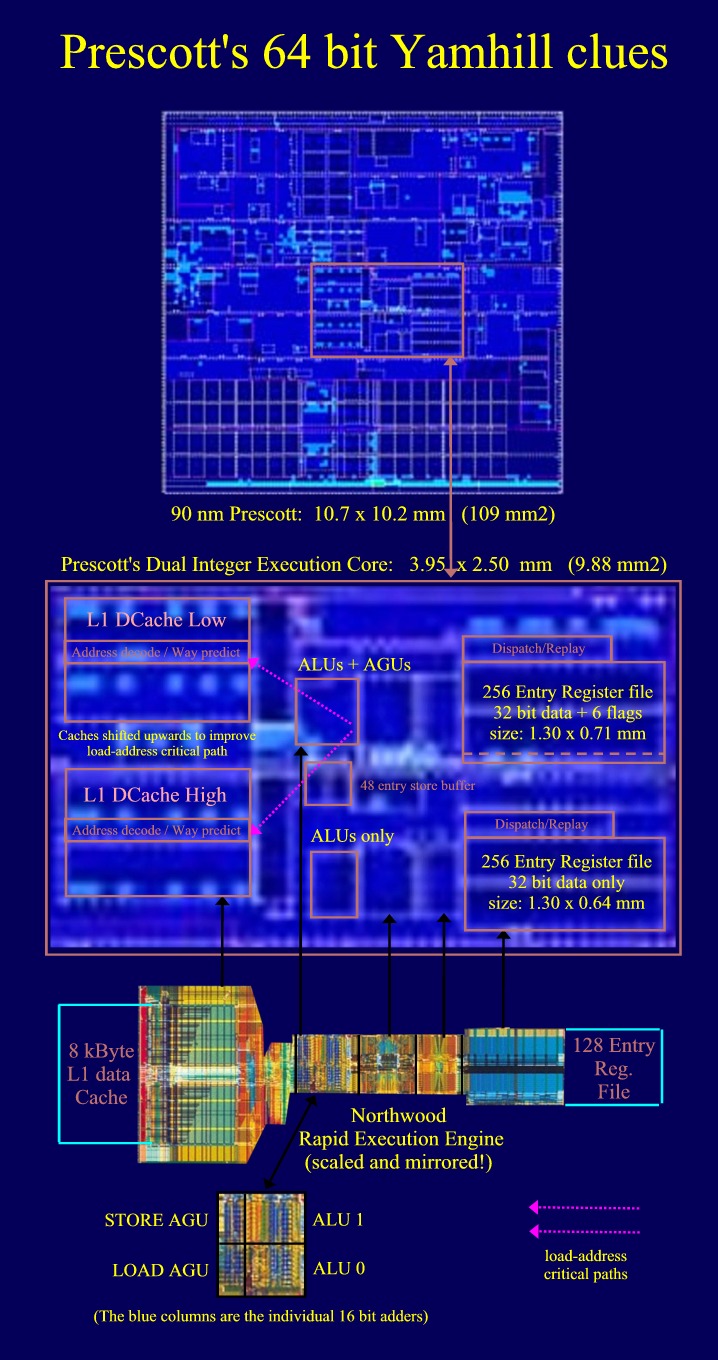
1: The second Integer Unit has no AGU's (Fast double
clocked Address Generator Units)
This
unit provides the address bits 32 and higher. We will show that there is
no need to provide these bits very fast
in
the NetBurst Architecture with its replay capabilities. nor do we need
all bits 32 through 63 A virtual address size of 40 or 48 bits
would be sufficient for the time being. (It's 48 bits in the first
implementation of the Hammer family)
|
Clue
2: The second Integer Unit register file has a
smaller size, 1.30 x 0.64 mm versus 1.30 x 0.71 mm
The
(renamed) register file of the Pentium 4 has 128 entries for 32 bit data
plus 6 bit status flags. We could show that Prescott has two 256 entry
register files. The width of the two is equal meaning that they have
the same number of entries. The height of the second one is however less,
indicating that is has less data bits per entry. We presume that it has all its
32 data bits but that the 6 status flags are lacking. A 64 bit processor
needs only one set of status flags per 64 bit word. This
clue also implies that the second core can not be used to run an
independent 32 bit thread.
|
Clue
3: The data caches have been shifted in order to
balance a critical path in 64 bit processing
The
first core has to provide the address bits for the data caches of both
cores. Most critical in Northwood are bits 6..11 that select one
of 32 cache lines in a 2k page and bits 12..16 that are used to
predict which of the 4 ways contains the cache line ( 4 x 2kByte =
8 kByte cache size ). These paths should be as short as possible.
Going from one core to another introduces a long path for this critical
signal. However, it turns out that the path to both caches are equal in
length. They managed to do this by shifting both caches upwards. (see second
image below)
|
Pentium
5 improvements over Pentium 4
A
list of improvements we found on the die until now.
Only
two of them are officially disclosed by Intel.
(
so it's all unofficial )
|
|
|
Specifications
and
Enabled
Features
|
Pentium
4
Northwood
Prestonia
(DP)
Gallatin
(MP) |
Pentium
5
Prescott
(Q4-03)
Nocona
(DP) (Q4-03)
Potomac
(MP) (H2-04)
|
|
Data
Width |
32
bit |
Prescott
32 bit
Nocona
32 bit
Potomac
64
bit |
|
Logical
Processors
(number
of threads) |
Northwood:
1,2
Prestonia:
2
Gallatin:
2 |
Prescott:
2
Nocona:
2?
Potomac:
4 |
|
L1
Data Cache |
8
kByte |
Prescott
16
kByte
Nocona
32 16 kByte
Potomac
32 kByte |
|
Instruction
Trace Cache |
12
k uOps |
16
k uOps |
|
Trace
Cache Bandwidth |
3
uOps/cycle |
4
uOps/cycle |
|
L2
Unified Cache |
512
kByte |
1024
kByte |
|
Instructions
in Flight |
126 |
256
128
|
|
Integer
Register File |
128
x 32 bit |
256
x 64 bit |
| Floating
Point Register File |
128 x 128 bit |
256 x 128 bit |
| Load Buffer |
48 entries |
96 entries |
| Store Buffer |
24 entries |
48 entries |
(updated
May 7, 2003)
|
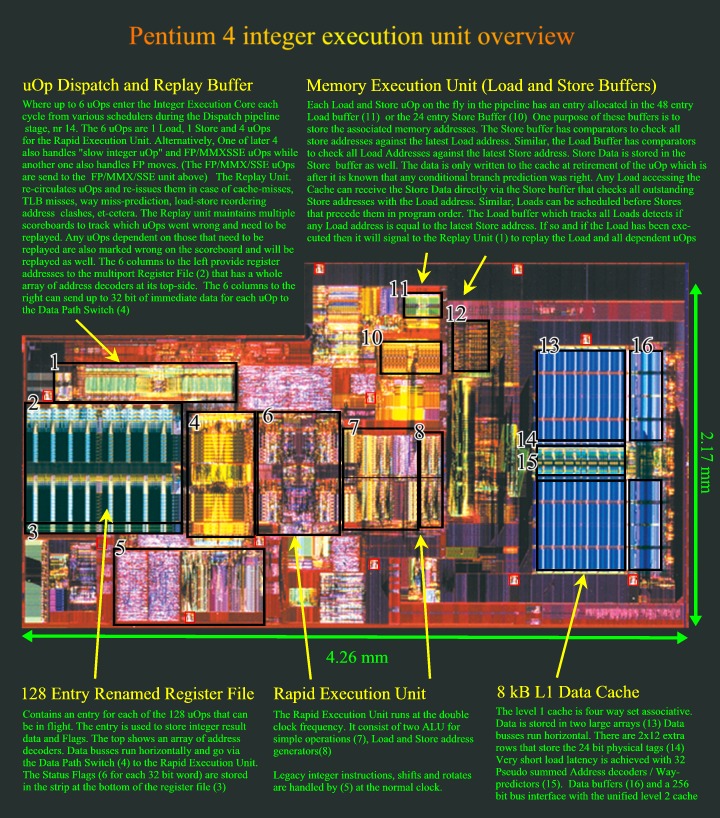
The
Image below will be featured in a coming article that will zoom in on
all the individual units and discuss them in detail
Must
be very interesting for all the assembly level programmers to see how
all their instructions fly around through the architecture. You can
click here for a higher resolution version.
|
|
|
The
next image below visualizes all three clues:
1)
The missing AGU's in the second core.
2)
The second register file with less bits per entry.
3)
The balanced timing critical load address to cache paths.
|
|
The
high address bits 32 and higher don't need to be calculated fast
I
said that I would explain that, however that will become much too
technical for now. Lets put things in a table, say for instance for a
Northwood Memory Execution Unit and larger then 32 bit addressing, see
below. Now, all actions that need the full address must be
designed in such a way that they are not timing critical. The
probably did manage to do that. Prescott has however a different cache
size and thus a different table. Have a look at David Sager's patents to
find out more about the stuff below.
|
load/
store |
Action
|
address
bit
used |
CSA/XOR
used
to by-
pass
AGU |
Optimization
Rule |
|
load |
write
load address
in
load buffer |
full
address |
no |
|
|
load |
Index
cache-line in
each
of the four ways |
6..11 |
yes |
2k
Data Cache aliasing, max four with same tag |
|
load |
Way
prediction |
12..15 |
yes |
64k
Data Cache aliasing, only one with same tag |
|
load |
Read
Store Data
from
Store Buffer |
2..13 |
yes? |
16k
store-forwarding aliasing, only one with same bits 2..13 in the
store buffer |
|
load |
Check
Store Buffer
Address
14..31 |
14:31 |
no |
4
Gbyte aliassing. Must take store buffer address bits 32 and
higher along to check later when full load address ready and
force a replay if needed |
|
load |
Check
Cache Hierarchy Hit |
full
address |
no |
General
cache stuff |
|
store |
write
store address
in
store buffer |
full
address |
no |
|
|
store |
Check
against the
load
buffer addresses |
2:16? |
no? |
Incorrect
match only produces unnecessary replays. Less bits = more
replays |
|
store |
Store
Data in
Cache
Hierarchy |
full
address |
no |
|
|
|
Why
does Intel say that the cache is 16kByte while there is 32 kByte on the
die??
Good
question. The answer has been written years ago in the CPUID
table!
| 66h: |
8kB first level data cache, 4-way set associative, 64 byte cache
line
|
| 67h: |
16kB first level data cache, 4-way set associative, 64 byte
cache line |
| 68h: |
32kB first level data cache, 4-way set associative, 64 byte
cache line |
How
can a 32 kB L1 cache be 4-way set associative with 4 kB page memory
management!.. Don't you
need at least 8 ways? (8 x 4 =32) Aren't we missing a
selection bit here. Ahaa... They
must be using a Thread ID bit so 2 threads get half of the cache (4
ways) and the other 2 get the other 4 ways. So Nocona will have a
32 kByte L1 Data Cache!
And
the other way around: It proves that Nocona will handle 4 threads!
Regards,
Hans
|
|
Related
articles
March
6, 2003: Looking
at Intel's Prescott die
April
20, 2003: Looking
at Intel's Prescott die, part II
|
|
{kind=link}
