|
March 06, 2003 (updated) Looking at Intel's Prescott die (by Hans de Vries)
|
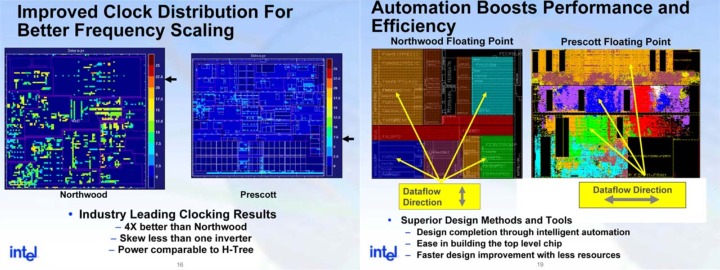
|
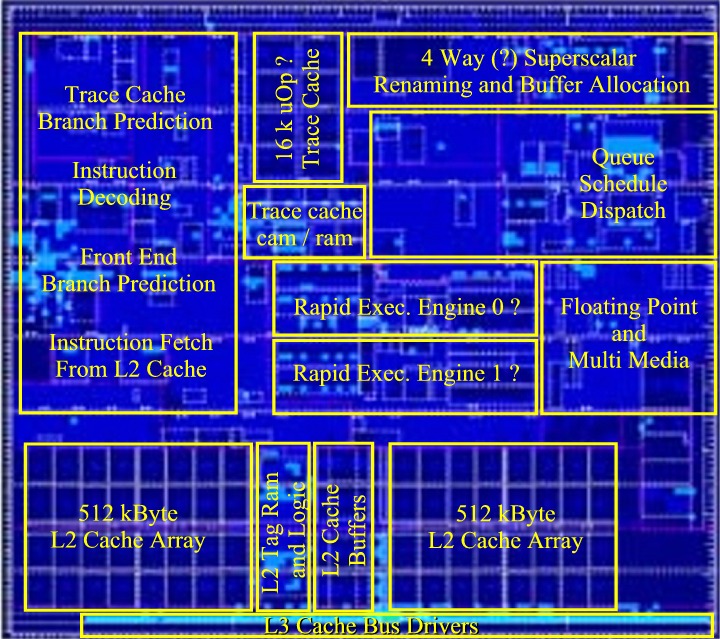
(1) Instruction Trace Cache Extended from 12 to 16k uOps ?.
|
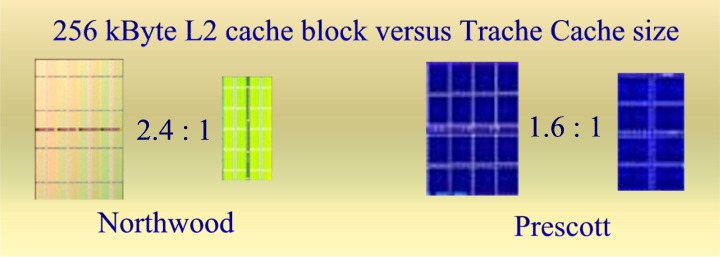
|
(2) Four instructions/cycle fetch and retire (up from 3).
|
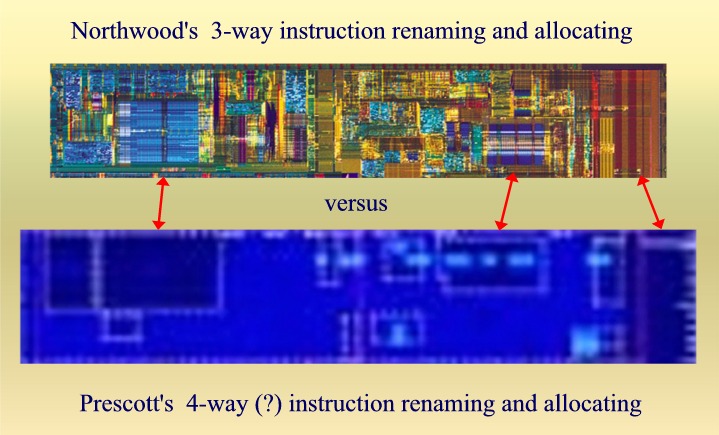
|
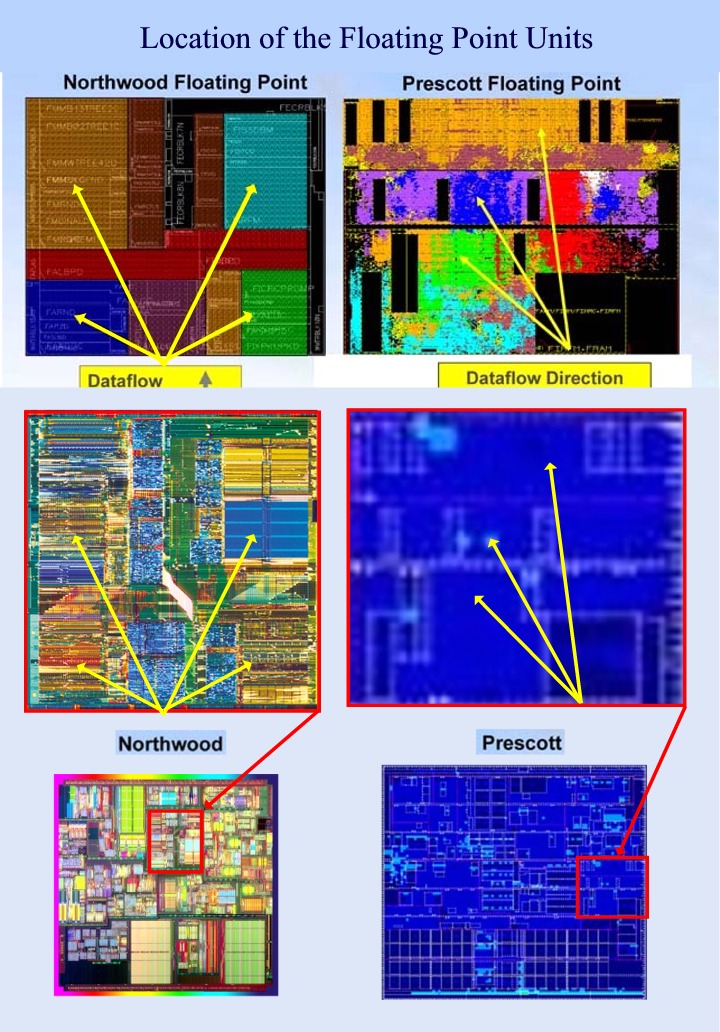
(3) Floating Point unit changed location on the Die.
|
|
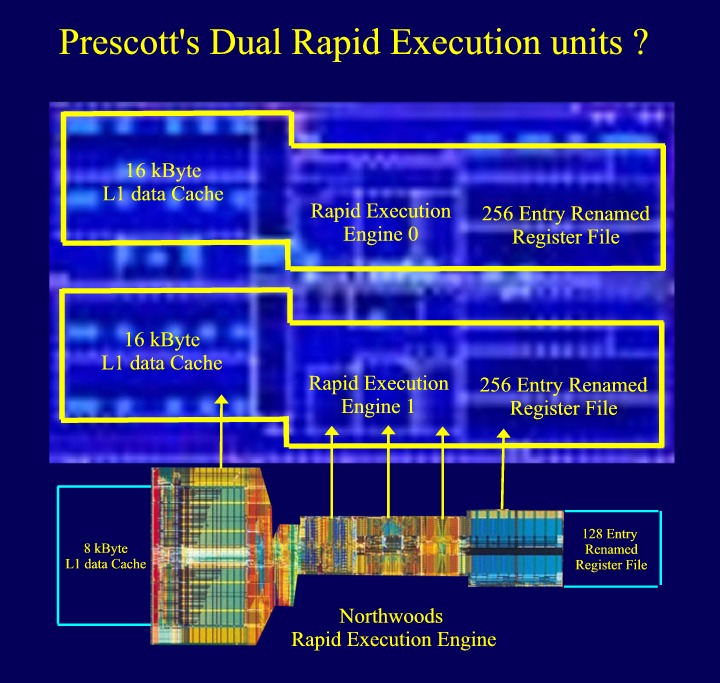
(4) Two (!) Rapid Execution Engine's ? .
|
|
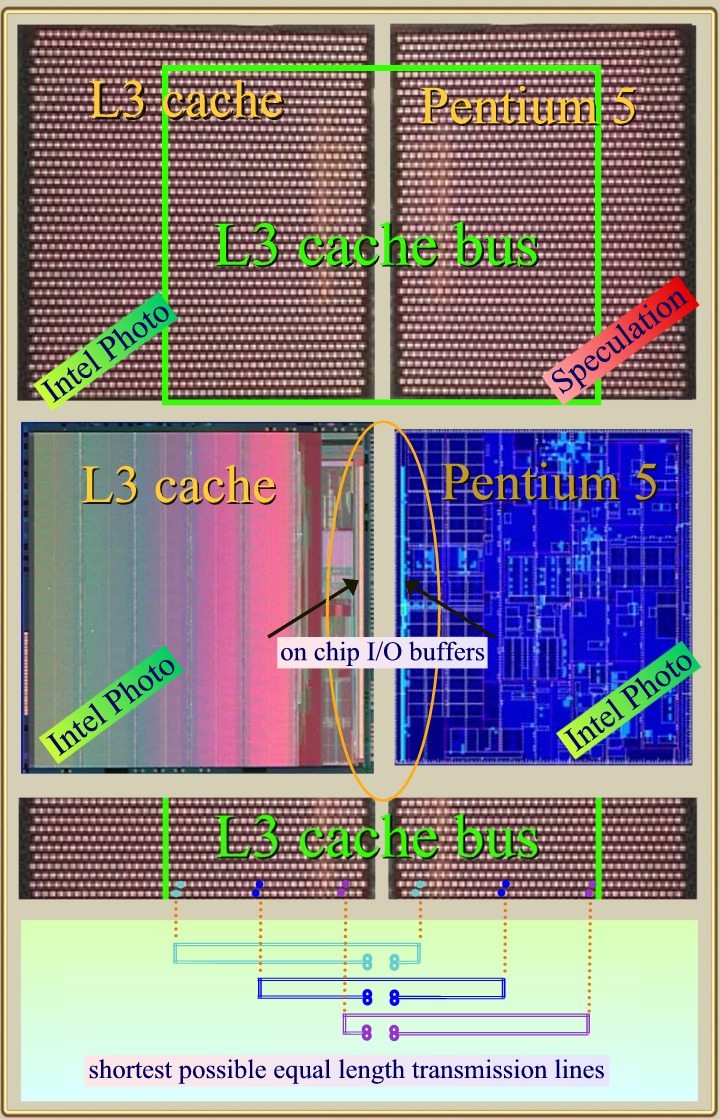
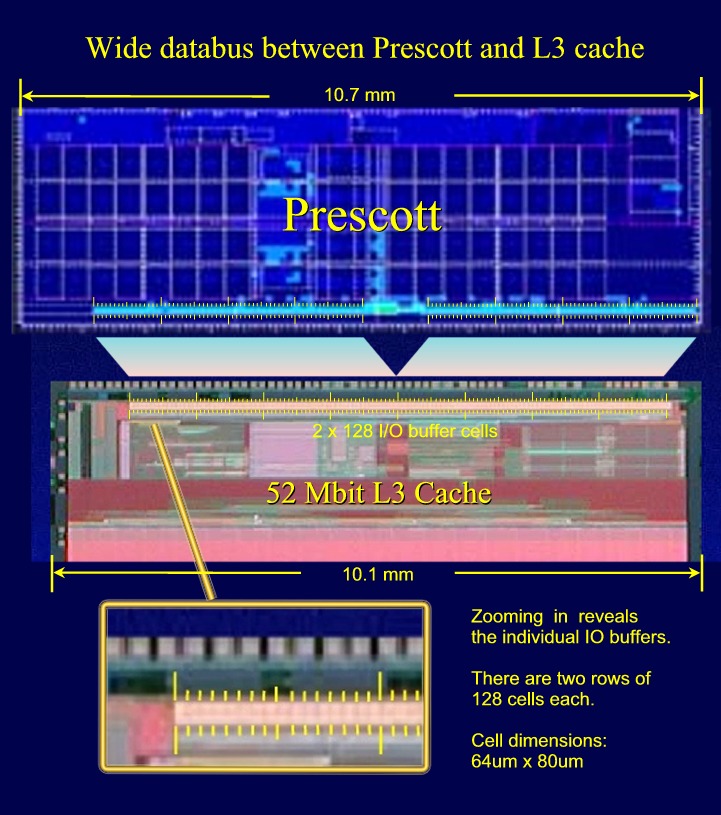
(5) Very wide high speed L3 Cache Bus ?.
|
|
(6) Prescott die size 109 mm2 (10.7 x 10.2 mm). (updated March 7, 2003)
|

![]()
